사용법
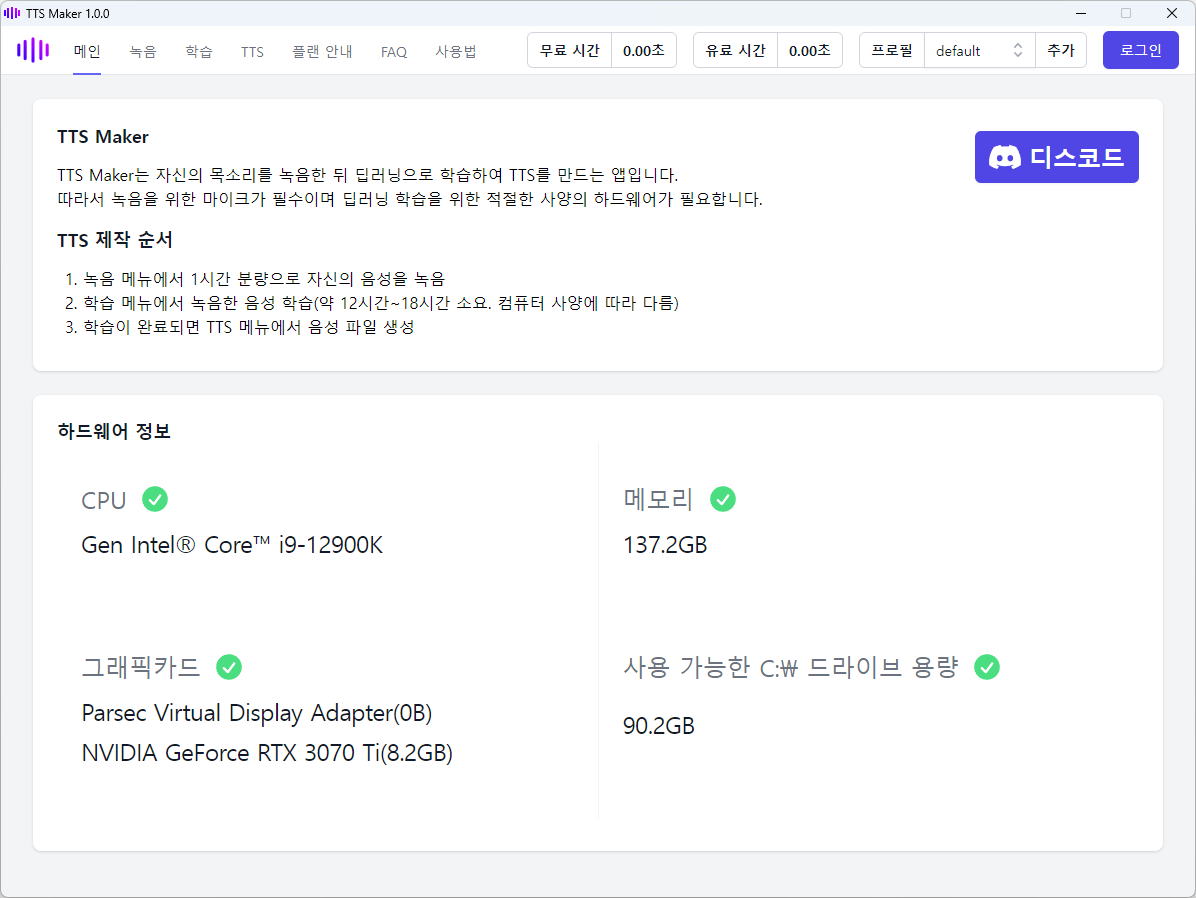
하드웨어 사양 체크
TTS Maker는 딥러닝을 활용하여 TTS 모델을 생성하므로 적절한 사양의 하드웨어가 필요합니다. 따라서 TTS Maker의 메인 화면에서는 필요한 하드웨어 사양을 표시해줍니다. TTS Maker를 정상적으로 사용하기 위한 하드웨어 사양은 다음과 같습니다.
- CPU: 인텔 x86-64 아키텍쳐 CPU를 사용해주세요.
- 메모리: 16GB 이상 메모리를 사용해주세요.
- 그래픽카드: 8GB 이상 메모리의 NVIDIA 그래픽카드를 사용해주세요.
- C:\ 용량: 10GB 이상 저장공간을 확보해주세요.
내 목소리 TTS 제작 과정
내 목소리를 TTS로 제작하는 과정은 크게 3가지로 구분됩니다.
- 내 목소리 녹음: 녹음 메뉴에서 내 목소리를 녹음합니다.
- TTS 모델 학습: 학습 메뉴에서 내 목소리를 TTS 모델로 학습합니다.
- TTS로 음성 합성: TTS 메뉴에서 텍스트를 음성으로 변환합니다.
내 목소리 녹음하기
녹음 메뉴에서 내 목소리를 녹음합니다.
- 문장: 문장은 총 600 문장이 준비되어 있습니다. 학습 가능한 최소 문장 개수는 20개입니다. 녹음한 문장 개수가 많을 수록 TTS에서 기계음이 사라집니다. 특히, 모든 문장은 정확히 읽어야 합니다. 은(는), 이(가) 등의 조사를 빠뜨리거나, 없는 조사를 더해서 읽지 않도록 합니다. 이는 TTS 정확도에 직접적인 영향을 주므로 주의해야 합니다.
- 테스트 녹음: TTS를 테스트해보고 싶은 분들은 60 문장만 녹음해봅니다. 이 정도는 녹음해야 자신의 목소리가 어느정도 나옵니다. 단, 기계음이 섞여 나올 수 있으므로 주의해야 합니다.
- 정식 녹음: 고음질 TTS를 사용하고 싶은 분들은 600 문장을 모두 녹음합니다.
- 총 녹음 시간: 말하기 속도에 따라 다르지만 600 문장으로 대략 50분에서 1시간 분량을 녹음하게 됩니다.
- 말하기 속도: 말하기 속도는 생성되는 TTS의 발음 속도에 직접적인 영향을 미칩니다. 즉, 빠르게 녹음하면 TTS도 빠르게 발음하고, 느리게 녹음하면 TTS도 느리게 발음합니다. 말하기 속도는 초당 3.8 글자에서 3.9 글자가 적당합니다.
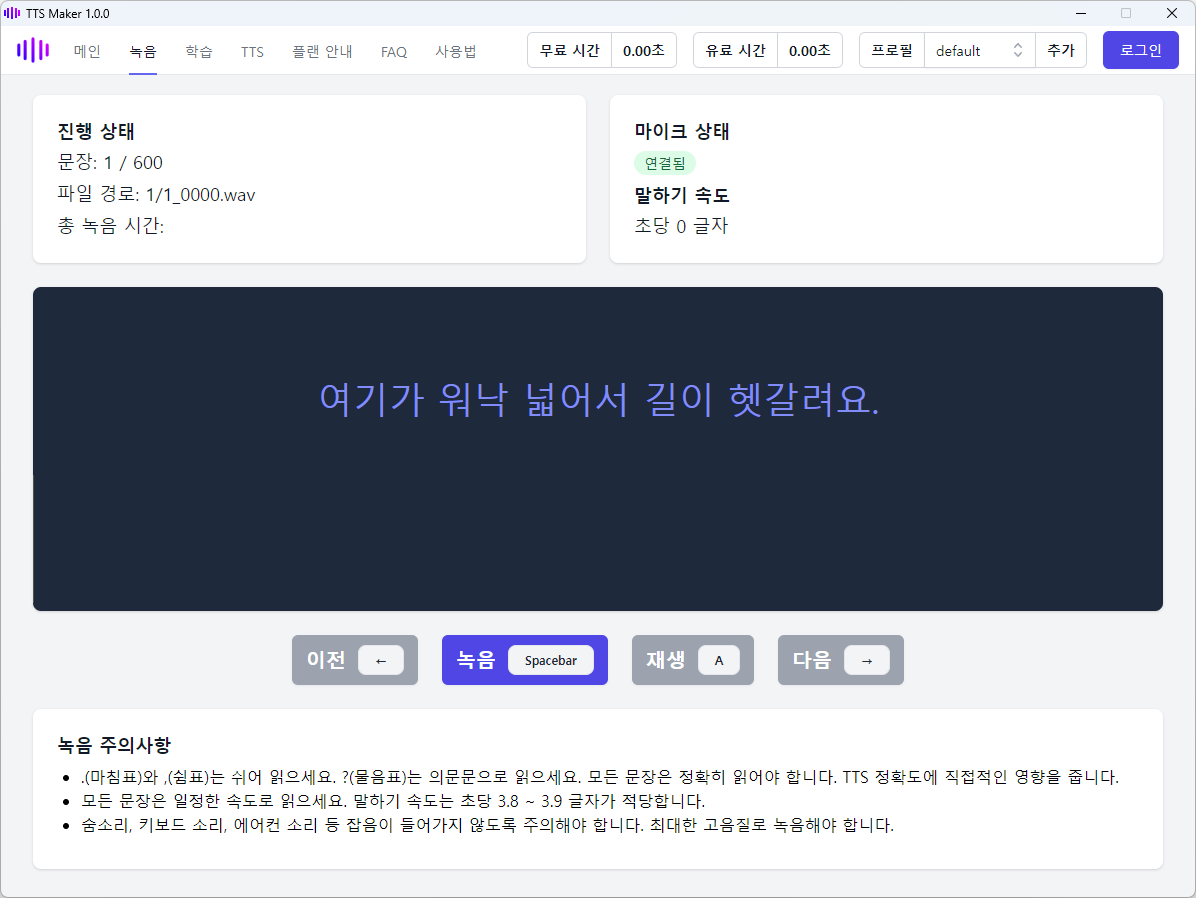
녹음할 때 주의할 점입니다.
- 문장 부호: .(마침표)와 ,(쉼표)는 쉬어 읽으세요. ?(물음표)는 의문문으로 읽으세요.
- 읽는 속도: 모든 문장은 일정한 속도로 읽으세요.
- 잡음 제거, 고음질: 숨소리, 키보드 소리, 에어컨 소리 등 잡음이 들어기지 않도록 주의해야 합니다. 최대한 고음질로 녹음해야 합니다.
- 숨소리는 팝필터로 제거할 수 있습니다.
- 콘덴서 마이크와 오디오 인터페이스를 사용하면 음질을 높일 수 있습니다.
TTS 모델 학습하기
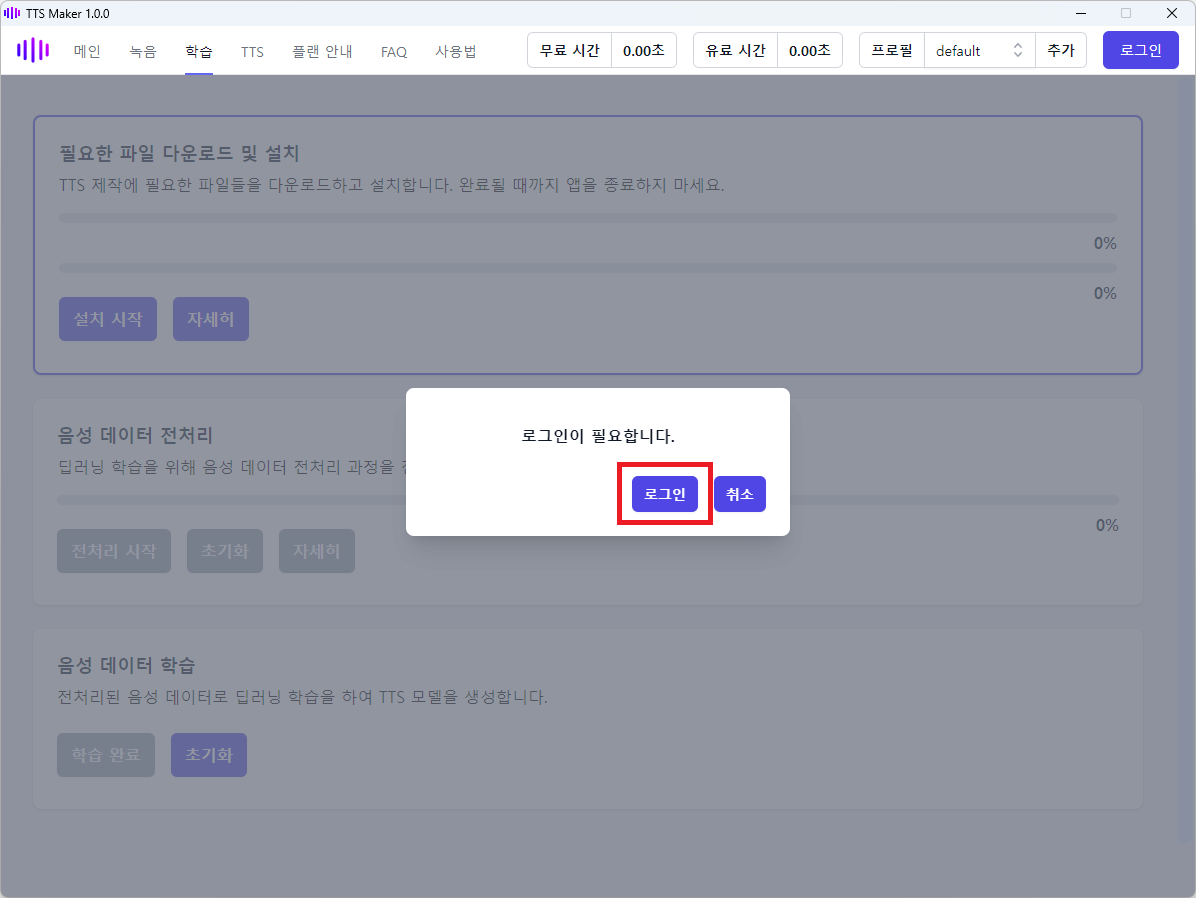
학습 메뉴에서 내 목소리를 TTS 모델로 학습합니다. 학습 메뉴는 로그인이 필요하므로 로그인 버튼을 클릭하여 로그인을 진행합니다(회원가입은 로그인과 동시에 진행됩니다).
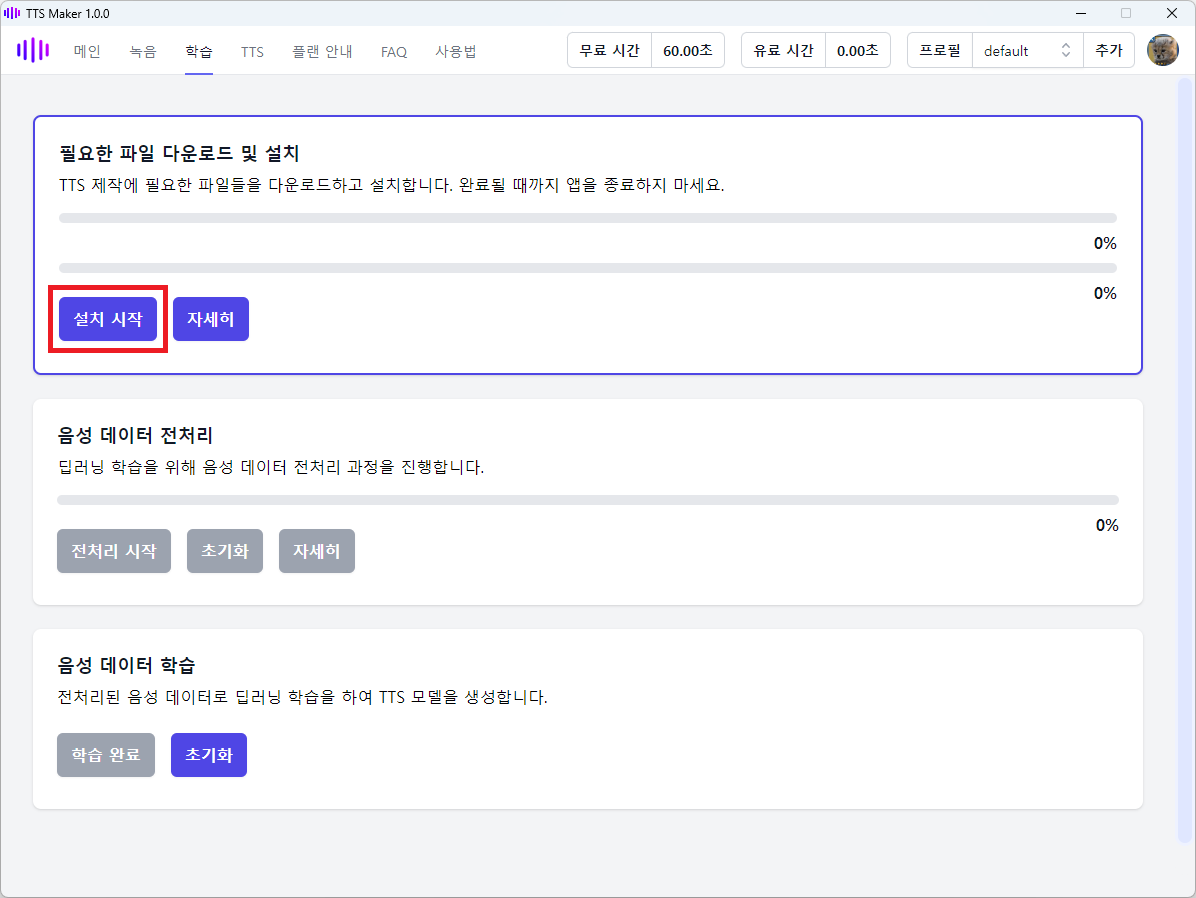
필요한 파일을 다운로드하고 설치를 진행합니다. 다음 그림과 같이 설치 시작 버튼을 클릭합니다.
일정 %에서 진행률 그래프가 멈춘 것처럼 보일 수 있습니다. 이는 PyTorch의 용량이 커서 다운로드와 설치가 오래 걸리기 때문입니다. 잠시 기다리면 모두 설치됩니다.
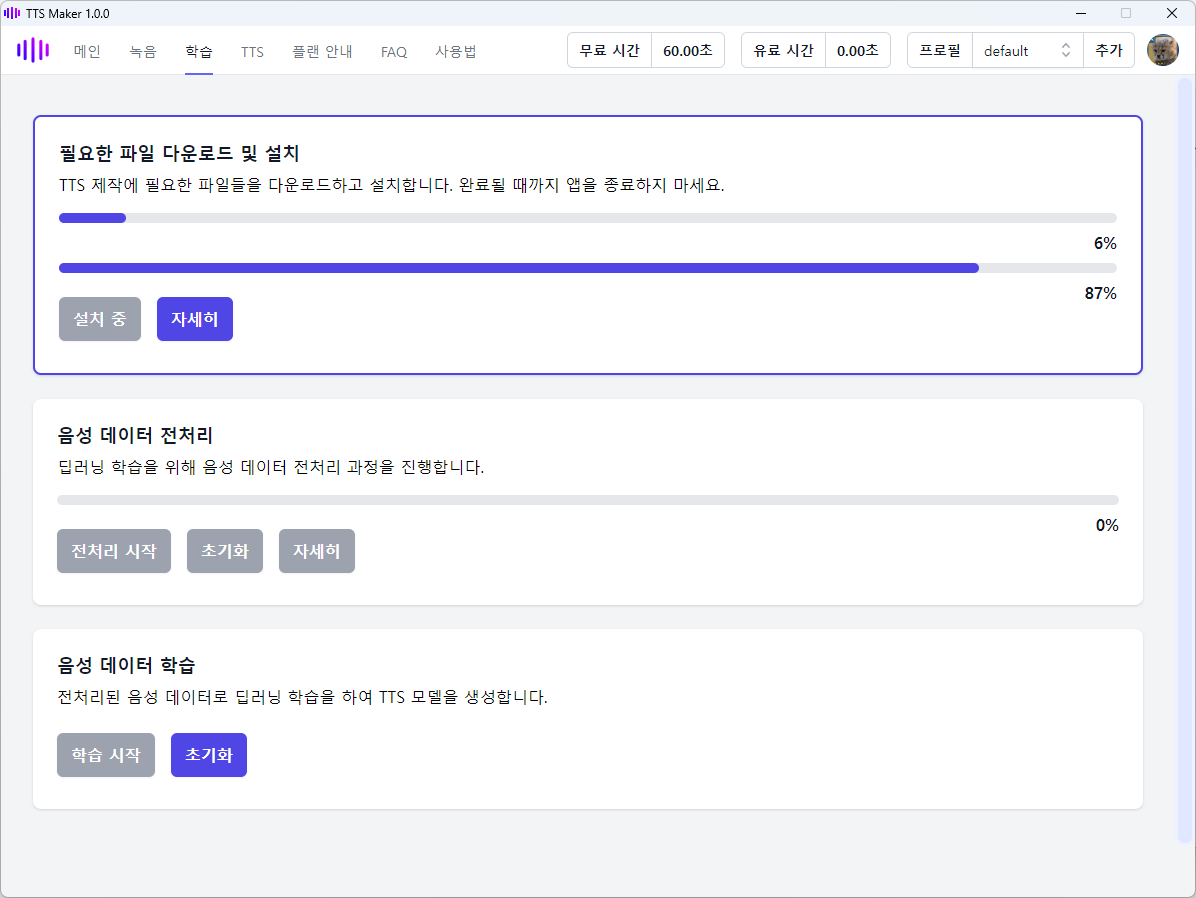
다음 그림과 같이 전처리 시작 버튼을 클릭하여 음성 파일을 TTS 모델 학습에 적합하도록 전처리 과정을 진행합니다.
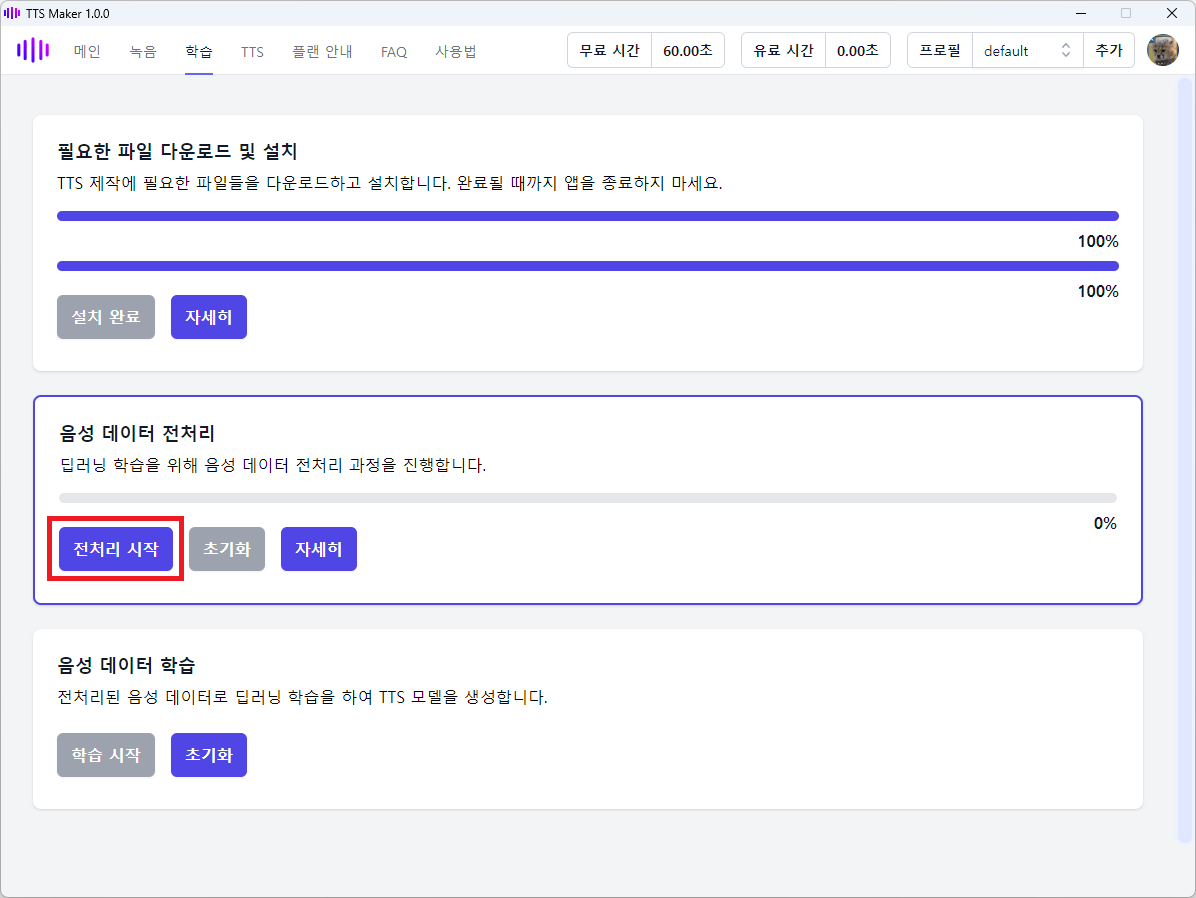
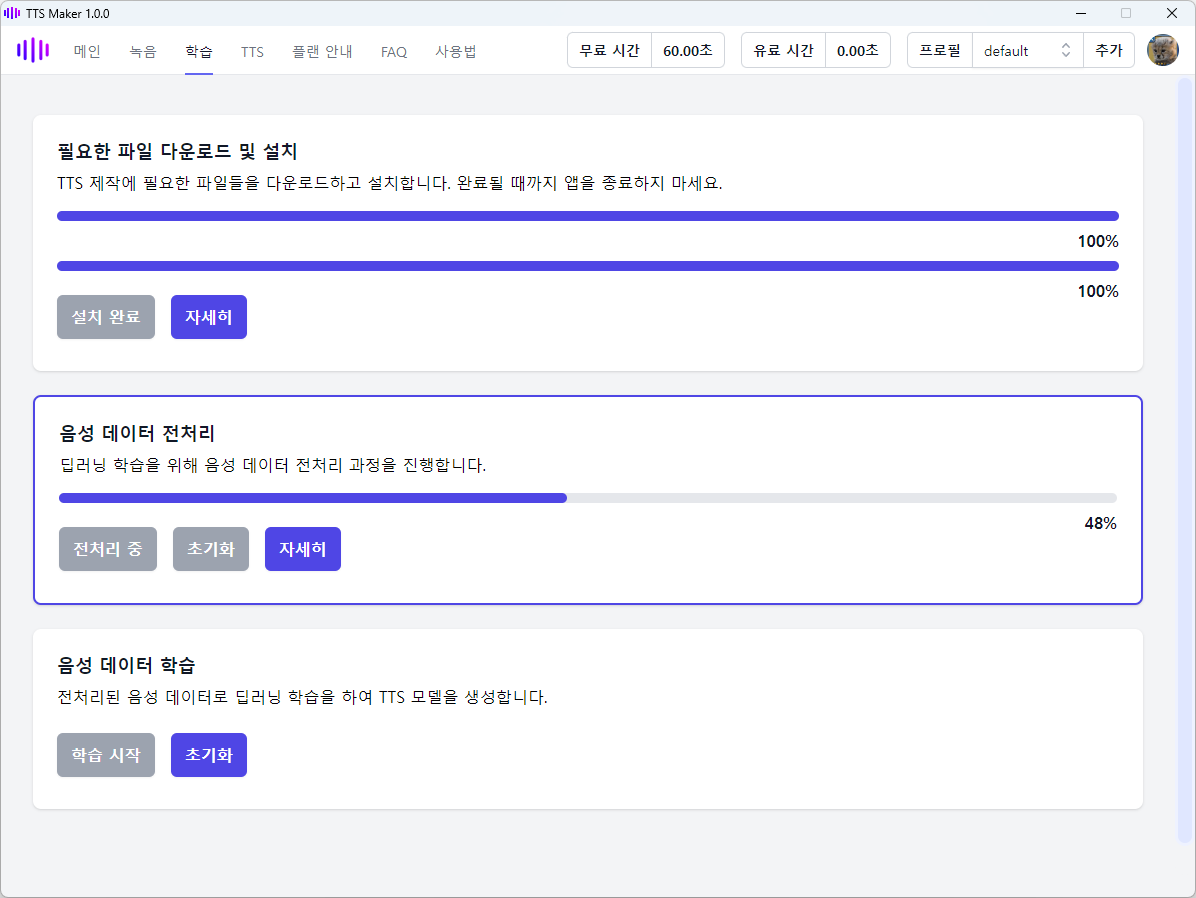
전처리도 0%에서 진행률 그래프가 멈춘 것처럼 보일 수 있습니다. 잠시 기다리면 계속 진행됩니다.
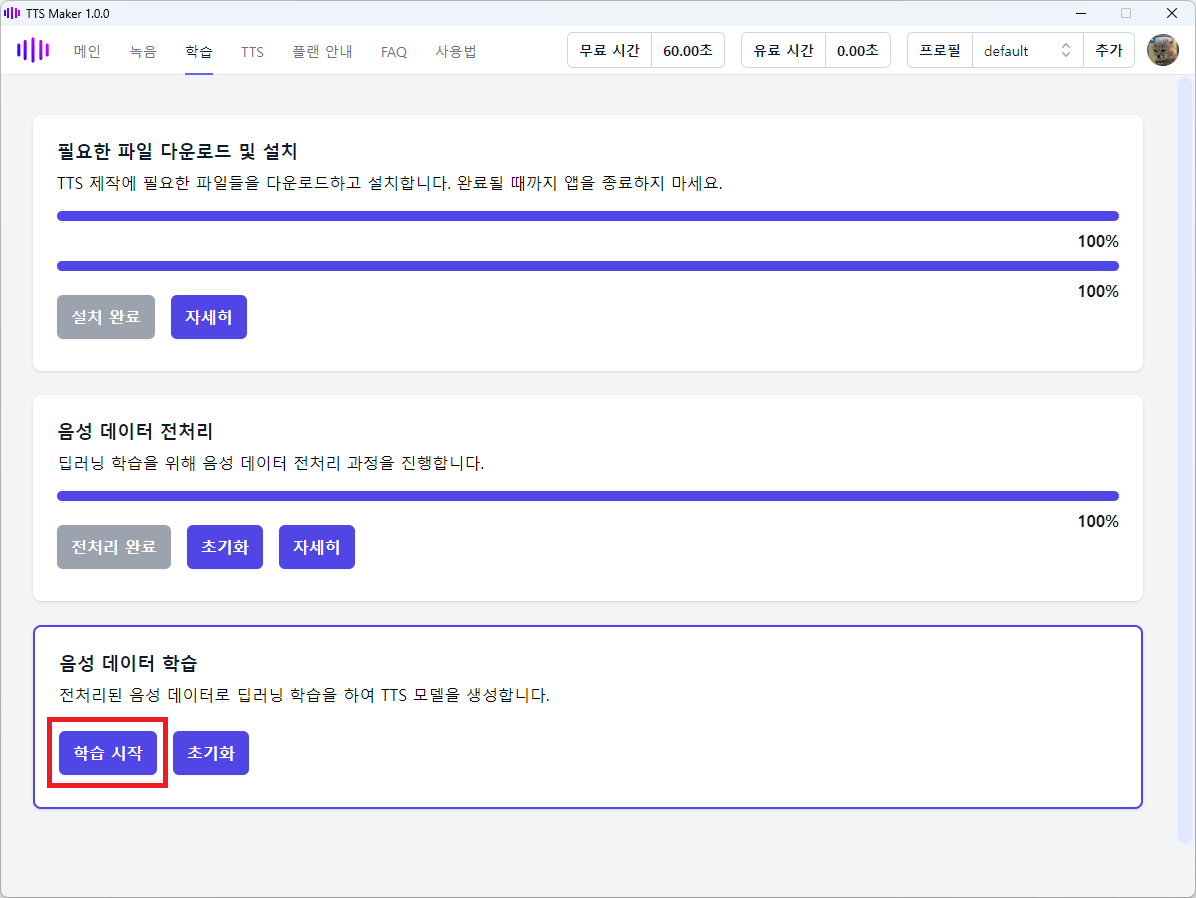
이제 TTS 모델 학습을 진행할 차례입니다. 다음 그림과 같이 학습 시작 버튼을 클릭합니다.
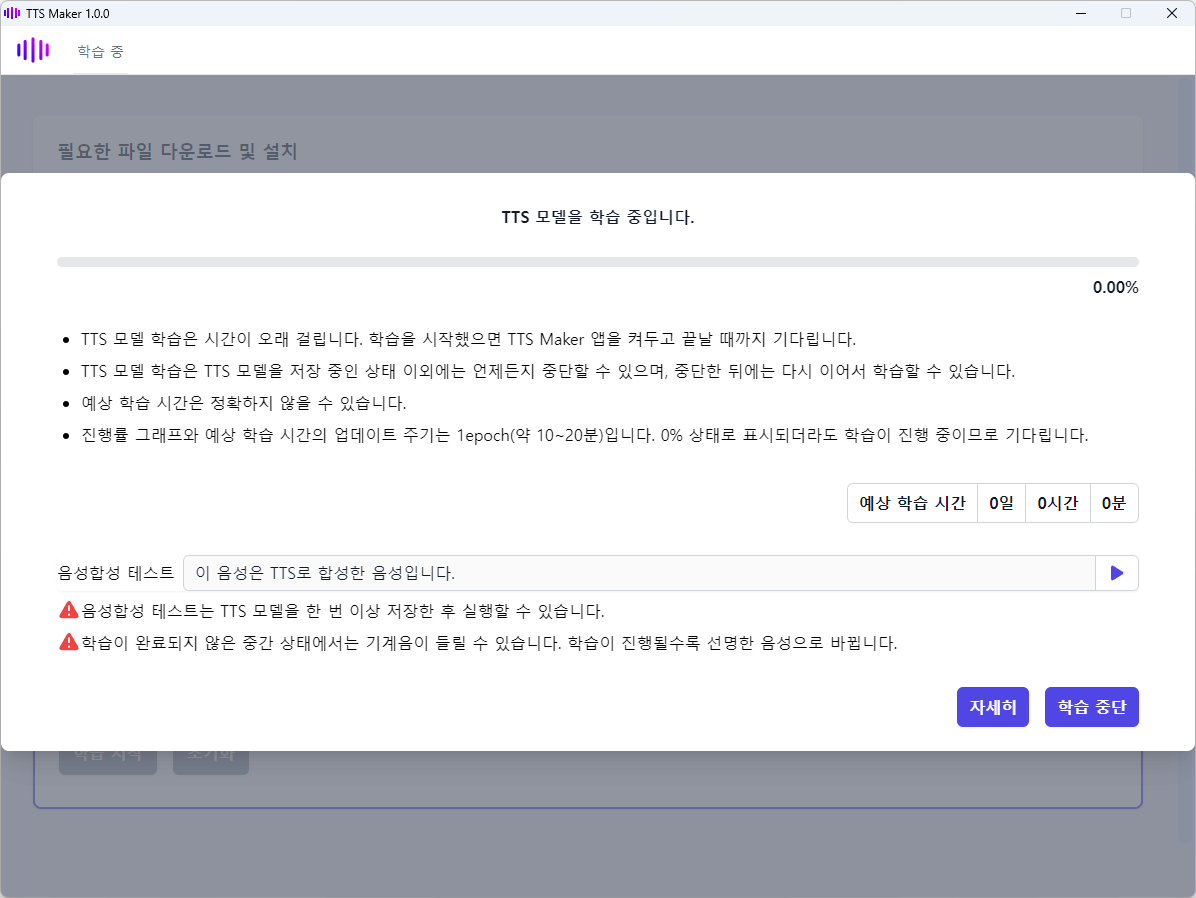
TTS 모델 학습 화면입니다.
- 진행률 그래프: 진행률 그래프는 %로 표시되며 업데이트 주기는 1epoch(약 10~20분)입니다. 0% 상태로 표시되더라도 학습이 진행 중이므로 기다립니다. 학습은 총 100epoch 진행합니다.
- 예상 학습 시간: 예상 학습 시간은 학습이 완료되기까지 남은 시간을 예측하여 표시합니다. 예상 학습 시간은 정확하지 않을 수 있습니다. 예상 학습 시간의 업데이트 주기는 1epoch(약 10~20분)입니다.
- 음성합성 테스트: TTS 모델 학습 중에 음성합성을 테스트해 볼 수 있습니다.
- 음성합성 테스트는 TTS 모델을 한 번 이상 저장한 후 실행할 수 있습니다.
- 학습이 완료되지 않은 중간 상태에서는 기계음이 들릴 수 있습니다. 학습이 진행될수록 선명한 음성으로 바뀝니다.
- 학습 중단 및 재개: TTS 모델이 저장 중인 상태 이외에는 학습 중단 버튼을 클릭하여 학습을 중단할 수 있습니다. 중단한 뒤에는 다시 이어서 학습할 수 있습니다.
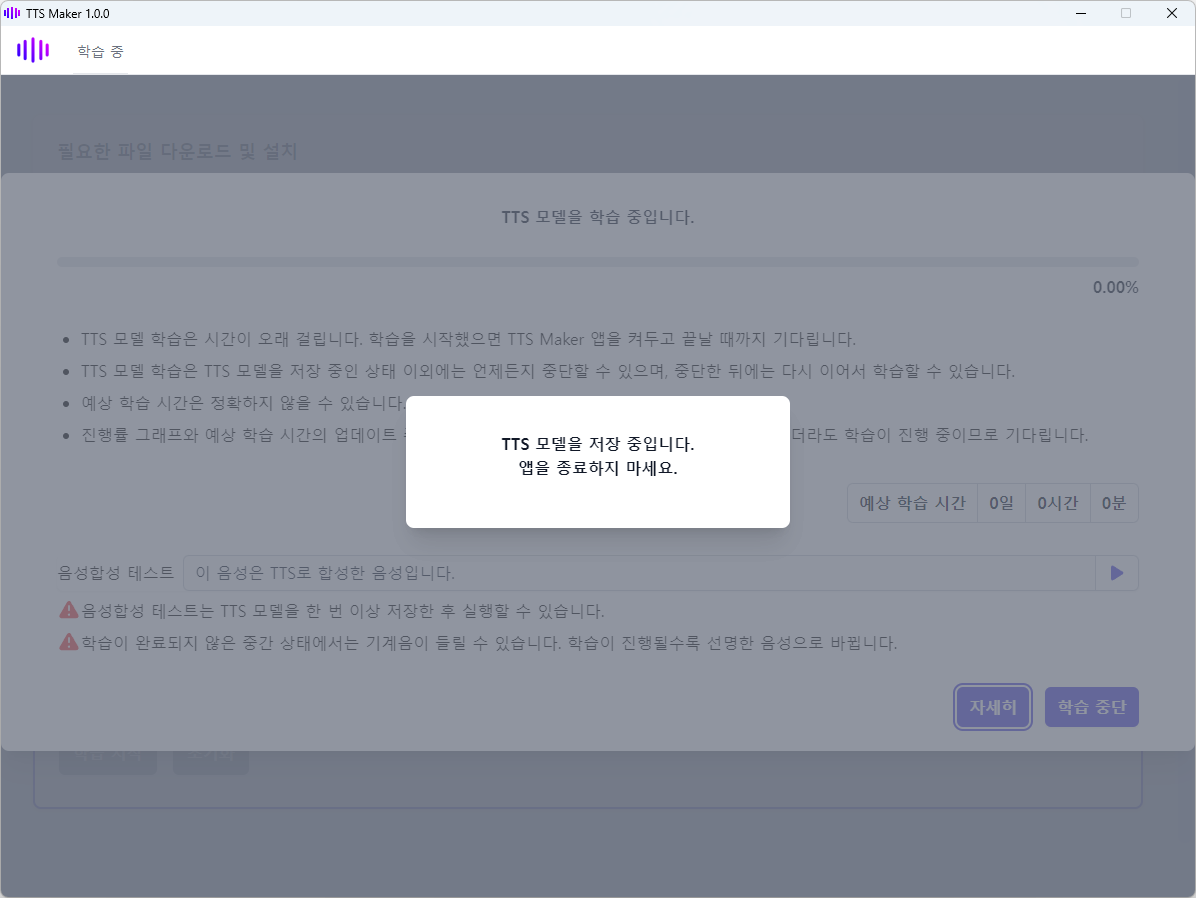
TTS 모델 학습이 1epoch씩 진행될 때마다 TTS 모델이 저장되면서 다음과 같은 화면이 표시됩니다. 이 때는 앱을 종료하면 안 됩니다.
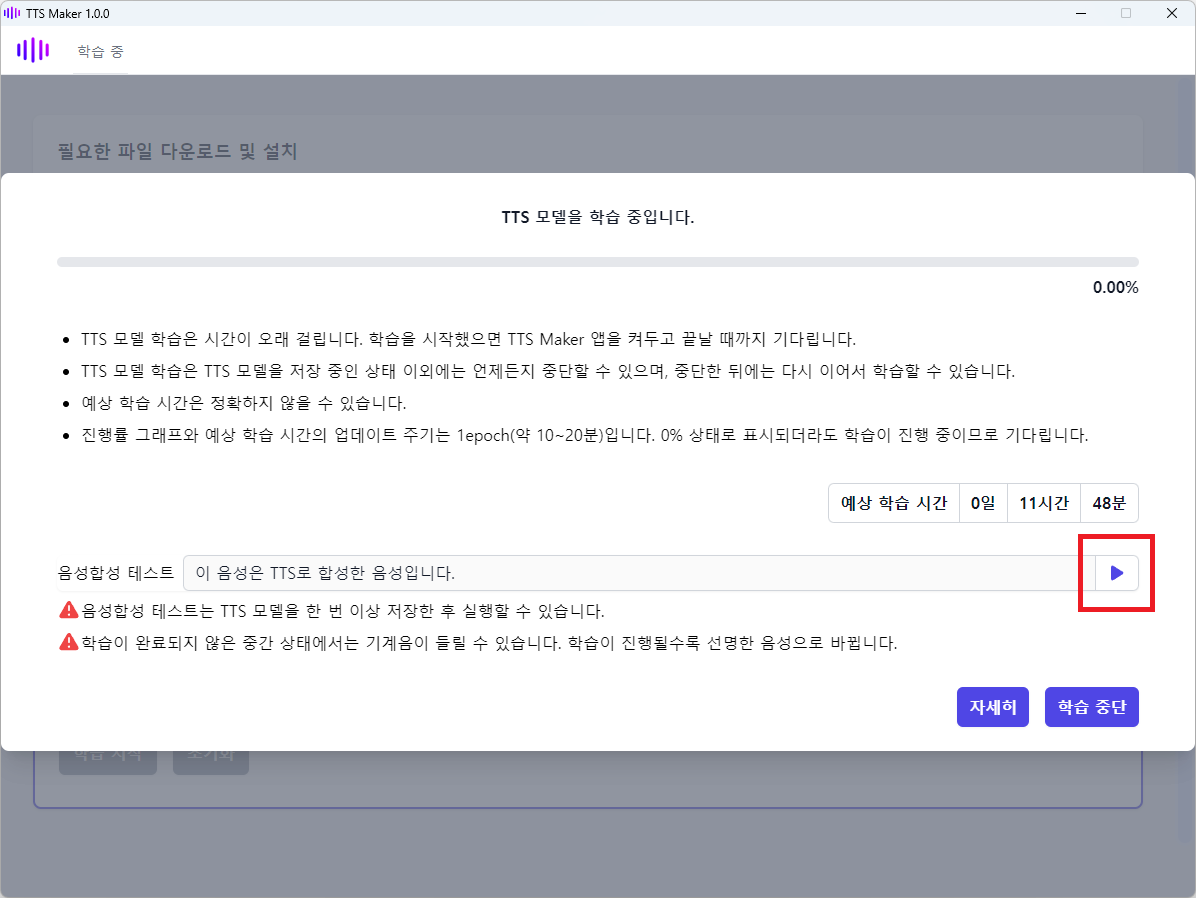
30분 정도 기다린 뒤 예상 학습 시간이 표시된다면, 음성합성 테스트를 해볼 수 있습니다. 오른쪽 아래 ▶ 버튼을 클릭합니다(20~30초 로딩 후 음성이 재생됩니다).
다음은 저의 목소리를 1epoch 학습한 뒤에 음성합성 테스트를 한 결과입니다. ▶ 버튼을 클릭하면 음성을 들을 수 있습니다.
음성합성 테스트
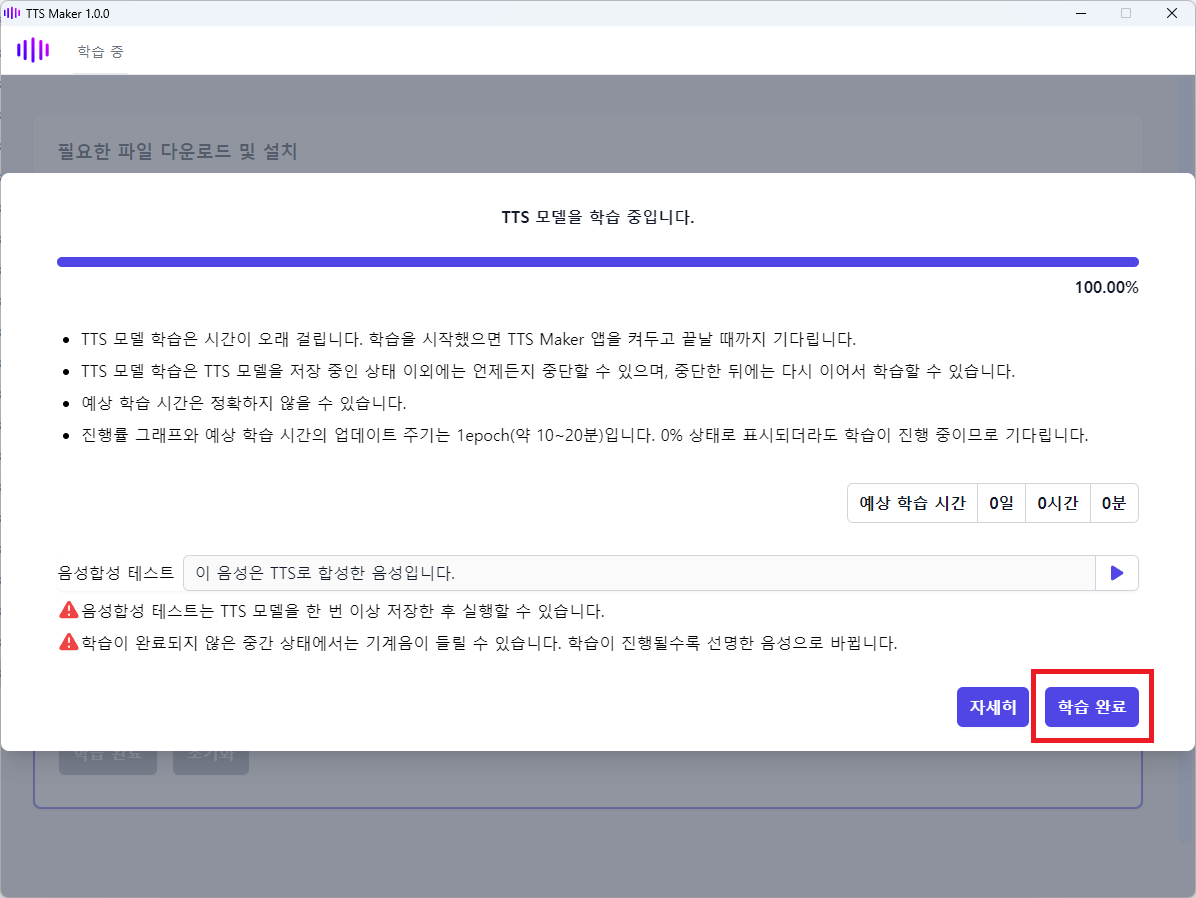
다음은 TTS 모델 학습이 완료된 화면입니다. 학습 완료 버튼을 클릭합니다.
TTS 음성합성하기
이제 TTS 메뉴에서 텍스트를 음성으로 변환할 수 있습니다. 텍스트를 입력하고 ▶ 클릭한 뒤 잠시 기다리면 음성이 재생됩니다.
다음은 저의 목소리를 100epoch까지 학습을 완료한 뒤 텍스트를 음성으로 변환해본 결과입니다. ▶ 버튼을 클릭하면 음성을 들을 수 있습니다.
4.79초
이렇게 내 목소리를 TTS로 만드는 과정이 모두 끝났습니다. 수고하셨습니다.